参照《第一行代码》开发CoolWeather (一)
本文共 6652 字,大约阅读时间需要 22 分钟。
CoolWeather 开发总结(一)
先看看开发完成后的界面吧


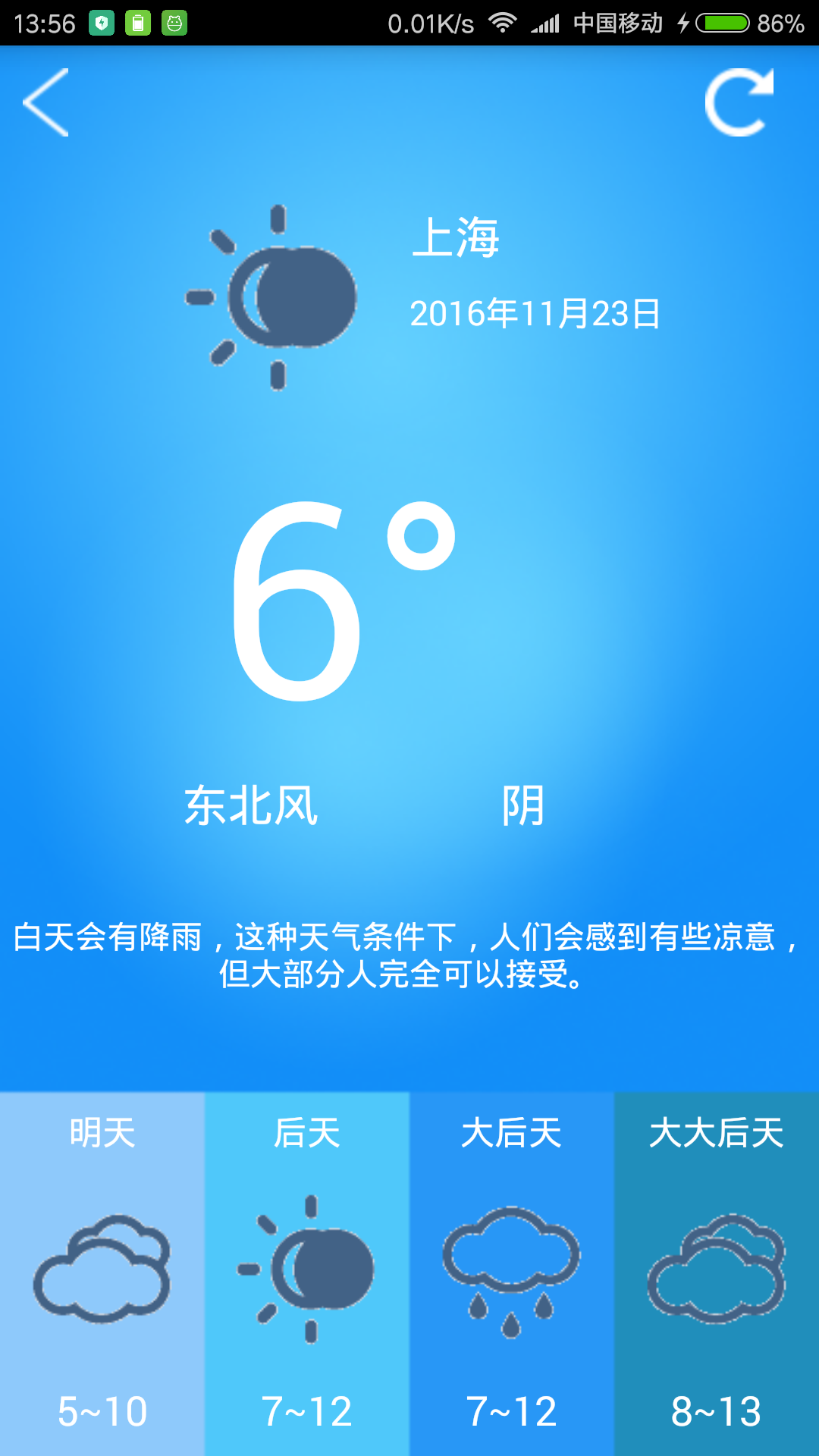
大体上和书上代码类似 但是由于书上所用的天气接口已经被关闭,所以换了一个和风天气的接口 并且重新设计了一下界面
**
1.功能需求及技术可行性分析
**
1)功能需求
1. 可以罗列出全国所有的省、市、县。 2. 可以查看全国任意城市的天气信息。 3. 可以自由地切换城市,去查看其他城市的天气。 4. 提供手动更新以及后台自动更新天气的功能。
2)技术可行性分析
1. 如何获取全国的省市县信息以及如何获取这些区域的天气信息 这里省市县的信息依然用的是 中国天气网的接口 因为它返回的数据比较简单 省份接口是 城市接口是: 省份代号.xml 县级接口是: 省份代号城市代号.xml注意如果直接用浏览器打开上面的网址显示的是
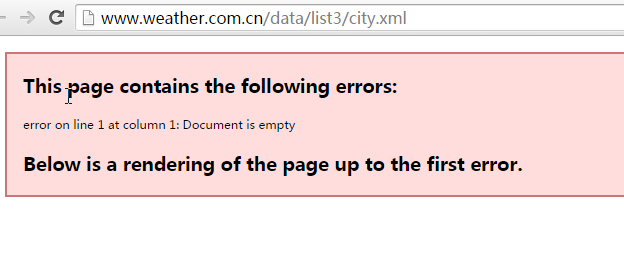 这里是猜测是因为浏览器解析xml出现了错误,我们可以写个小demo测试一下
这里是猜测是因为浏览器解析xml出现了错误,我们可以写个小demo测试一下 URL url = new URL("http://www.weather.com.cn/data/list3/city.xml"); HttpURLConnection conn = (HttpURLConnection) url.openConnection(); InputStream is = conn.getInputStream(); BufferedReader br = new BufferedReader(new InputStreamReader(is,"UTF-8")); String line = ""; while((line=br.readLine())!=null){ System.out.println(line); } 那么可以看到解析出来的数据就是这种”代号|名称“的格式 只要将数据解析出来放listview显示出来就可以了
这样省市县的数据就已经解决了
再看天气信息 书上写的接口
天气代号.html 这个接口已经关闭无法使用了 我这里用的是和风天气接口 只要去官网注册一下就可以免费使用它的接口 城市名称/城市代号&key=你认证的key 注意城市名称如果是中文的话应该转码成utf-8 当然拼音格式的就不用转码了 返回的数据是json格式的 比较复杂 我们稍微排列一下就容易明白了
比较复杂 我们稍微排列一下就容易明白了 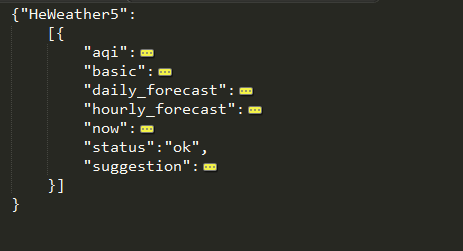 我只用了basic里的当前更新时间 daily_forecast更新的未来七天的天气 now当前气温 suggestion里的提示信息
我只用了basic里的当前更新时间 daily_forecast更新的未来七天的天气 now当前气温 suggestion里的提示信息 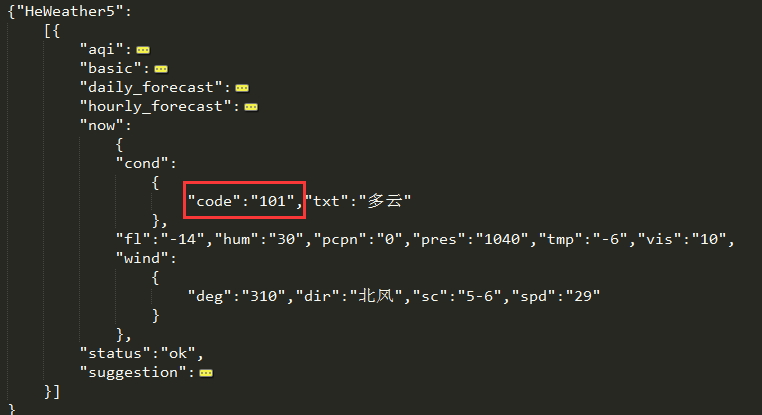 根据code代号可以通过相应的接口获取对于天气的图片
根据code代号可以通过相应的接口获取对于天气的图片 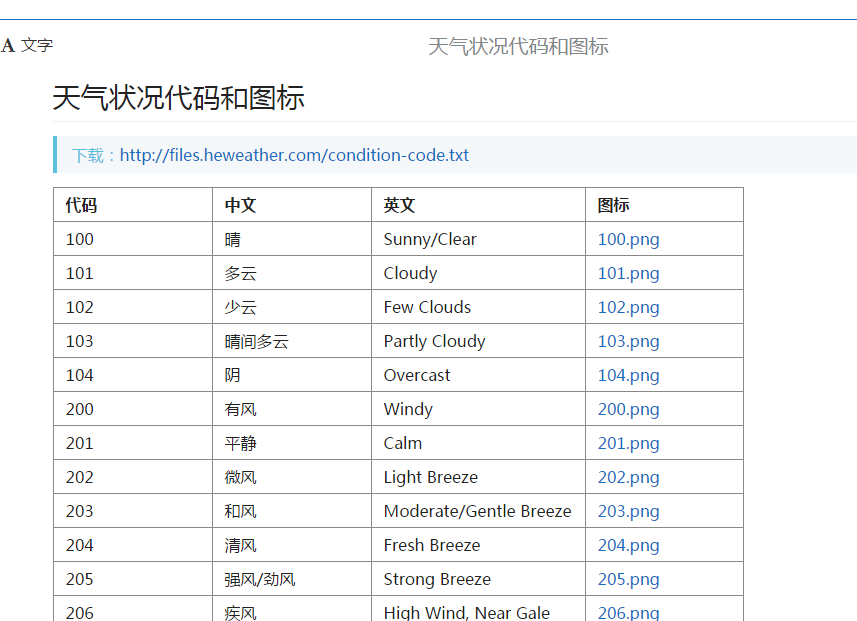
2.创建数据库和表
1.首先在项目下建包 将相应功能的类分开管理
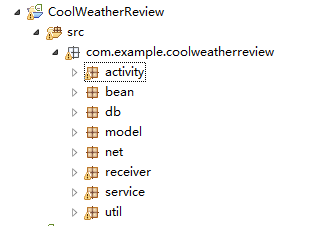 activity包用于存放所有活动相关的代码,db包用于存放所有数据库相关的代码,model包用于存放所有模型相关的代码,receiver包用于存放所有广播接收器相关的代码,service包用于存放所有服务相关的代码,util包用于存放所有工具相关的代码
activity包用于存放所有活动相关的代码,db包用于存放所有数据库相关的代码,model包用于存放所有模型相关的代码,receiver包用于存放所有广播接收器相关的代码,service包用于存放所有服务相关的代码,util包用于存放所有工具相关的代码 1.在db包下新建CoolWeatherOpenHelper类 通过该类在数据库生成省份、城市、县级三张表
public class CoolWeatherOpenHelper extends SQLiteOpenHelper { /** * Province建表语句 */ private static final String CREATE_PROVINCE = "create table Province (" + "id integer primary key autoincrement," + "province_code text," + "province_name text)"; /** * City建表语句 */ private static final String CREATE_CITY = "create table City(" + "id integer primary key autoincrement," + "city_code text," + "city_name text," + "province_id integer)"; /** * County建表语句 */ private static final String CREATE_COUNTY = "create table county(" + "id integer primary key autoincrement," + "county_code text," + "county_name text," + "city_id integer)"; public CoolWeatherOpenHelper(Context context, String name, CursorFactory factory, int version) { super(context, name, factory, version); } @Override public void onCreate(SQLiteDatabase db) { //创建三张表 db.execSQL(CREATE_PROVINCE); db.execSQL(CREATE_CITY); db.execSQL(CREATE_COUNTY); } @Override public void onUpgrade(SQLiteDatabase arg0, int arg1, int arg2) { }} ``` 2.然后再分别建立省份、城市和县所对应的实体类
- 接着我们还需要创建一个CoolWeatherDB类,把一些常用的数据库操作封装起来 首先私有化构造方法 单例模式 然后分别写了从数据库读取存放省份城市和县的方法
/** * 数据库类 * @author Administrator * 封装数据库操作 */ public class CoolWeatherDB { /** * 数据库名称 */ private static final String DB_NAME = "cool_weather"; /** * 数据库版本 */ private static final int VERSION = 1; private static CoolWeatherDB coolWeatherDB; private SQLiteDatabase db; /** * 构造方法私有化 * @param context */ private CoolWeatherDB(Context context) { CoolWeatherOpenHelper dbHelper = new CoolWeatherOpenHelper(context, DB_NAME, null, VERSION); db = dbHelper.getWritableDatabase(); } /** * 获得coolWeatherDB实例 * @param context 上下文环境 * @return */ public synchronized static CoolWeatherDB getInstance(Context context){ if(coolWeatherDB==null){ coolWeatherDB = new CoolWeatherDB(context); } return coolWeatherDB; } /** * 将Province保存到数据库 * @param province */ public void saveProvince(Province province){ if(province!=null){ ContentValues values = new ContentValues(); values.put("province_name", province.getProvinceName()); values.put("province_code", province.getProvinceCode()); db.insert("Province", null, values); } } /** * 从数据库中获得全国的省份信息 * @return */ public List loadProvinces(){ List list = new ArrayList (); Cursor cursor = db.query("Province", null, null, null, null, null, null); if(cursor.moveToFirst()){ do{ Province province = new Province(); province.setId(cursor.getInt(cursor.getColumnIndex("id"))); province.setProvinceCode(cursor.getString(cursor.getColumnIndex("province_code"))); province.setProvinceName(cursor.getString(cursor.getColumnIndex("province_name"))); list.add(province); }while(cursor.moveToNext()); } return list; } /** * 将城市信息保存到数据库 * @param city */ public void saveCity(City city){ if(city!=null){ ContentValues values = new ContentValues(); values.put("city_code", city.getCityCode()); values.put("city_name", city.getCityName()); values.put("province_id", city.getProvinceId()); db.insert("City", null, values); } } /** * 从数据库获得城市信息 * @return */ public List loadCities(int provinceId){ List list = new ArrayList (); Cursor cursor = db.query("City", null, "province_id=?", new String[]{String.valueOf(provinceId)}, null, null, null); if(cursor.moveToFirst()){ do{ City city = new City(); city.setId(cursor.getInt(cursor.getColumnIndex("id"))); city.setCityCode(cursor.getString(cursor.getColumnIndex("city_code"))); city.setCityName(cursor.getString(cursor.getColumnIndex("city_name"))); city.setProvinceId(provinceId); list.add(city); }while(cursor.moveToNext()); } return list; } /** * 将县级信息保存到数据库 * @param county */ public void saveCounty(County county){ if(county!=null){ ContentValues values = new ContentValues(); values.put("county_code", county.getCountyCode()); values.put("county_name", county.getCountyName()); values.put("city_id", county.getCityId()); db.insert("County", null, values); } } /** * 从数据库中加载县级信息 * @param cityId * @return */ public List loadCounties(int cityId){ List list = new ArrayList (); Cursor cursor = db.query("County", null, "city_id=?", new String[]{String.valueOf(cityId)}, null, null, null); if(cursor.moveToFirst()){ do{ County county = new County(); county.setId(cursor.getInt(cursor.getColumnIndex("id"))); county.setCountyCode(cursor.getString(cursor.getColumnIndex("county_code"))); county.setCountyName(cursor.getString(cursor.getColumnIndex("county_name"))); county.setCityId(cityId); list.add(county); }while(cursor.moveToNext()); } return list; }} 这样第一阶段的代码就写好了
你可能感兴趣的文章
Spark Streaming调优
查看>>
Spark
查看>>
Spark自定义排序/分区
查看>>
Flume与HBASE、Kafka集成
查看>>
SparkStreaming 如何保证消费Kafka的数据不丢失不重复
查看>>
Spark Shuffle及其调优
查看>>
数据仓库分层
查看>>
常见数据结构-TrieTree/线段树/TreeSet
查看>>
Hive数据倾斜
查看>>
TopK问题
查看>>
Hive调优
查看>>
HQL排查数据倾斜
查看>>
DAG以及任务调度
查看>>
LeetCode——DFS
查看>>
MapReduce Task数目划分
查看>>
ZooKeeper分布式锁
查看>>
3126 Prime Path
查看>>
app自动化测试---ADBInterface驱动安装失败问题:
查看>>
RobotFramework+Eclipse安装步骤
查看>>
测试的分类
查看>>